Does this prime contract require us to provide the lender or client with copies of the subcontracts?
That was the question. A general contractor, mid-project, with real money and real legal exposure on either side of the answer asked it of two systems side by side.
The first was a purpose-built, domain-tuned, in-house RAG assistant built by a construction contract intelligence platform after reading a couple of whitepapers on retrieval. It had been built specifically to answer questions like this one against executed prime contracts. It said yes.
The second was Microsoft Copilot. It said no.
The general contractor noticed the discrepancy and escalated. The platform's own legal counsel reviewed both answers against the contract. Copilot was right. The in-house assistant had cited contract language that implied a disclosure obligation but synthesized a confident wrong conclusion. AIA A201 §5.2.1 only requires identification of subcontractors. It does not require delivery of the subcontract documents themselves. Copilot retrieved the relevant clauses — §5.2.1, §9.6.4, §5.4 — reasoned across them, and arrived at the correct bottom line. The purpose-built system retrieved the wrong evidence and never recovered.
The lesson is not that Copilot is a credible alternative to purpose-built RAG. It isn't. The lesson is how invisible these failures are. A commodity tool retrieved the right evidence while a domain-specialized in-house system retrieved the wrong evidence. The model didn't hallucinate freely. It synthesized confidently from incorrect retrieved evidence. The output looked right. It cited a source. It was wrong on the question that mattered.
This is the failure mode that kills enterprise deals in regulated verticals, and the one in-house RAG pipelines are least architected to catch. It doesn't surface in development. It surfaces during the procurement-driven pilot, when a customer's domain expert checks an answer against the source and finds the system confident, fluent, and wrong.
Why the demo passes and the deal fails
When teams build RAG in-house, they evaluate against the data they have, the queries they expect, and the load they generate themselves. That environment is unrepresentative in four specific ways, and procurement at regulated buyers has learned to test for all four.
The corpus you ship against is not the corpus your customer will load. The latency you measured is not the latency your customer sees under concurrent load. The retrieval that returns plausible-looking chunks is not the retrieval that survives a domain expert checking the answer against the source. And citation built as a UI feature is not citation built as an architectural commitment, which is what procurement actually asks for once they get past the demo.
The way an engineering team perceives a retrieval problem is not the way a customer experiences it.
The bridge between those two is the gap that "demo passes, deal fails" lives in.
The corpus you tested isn't the corpus you'll receive
The platform's in-house stack had no OCR on the retrieval side. Scanned documents were uningestible. Tables embedded in narrative prose were either dropped or flattened into unusable text. Diagrams, charts, and signatures on scanned forms were invisible to the retriever. The system worked beautifully on clean digital PDFs the engineering team had used in development, but collapsed on the real corpus the customer loaded after onboarding.
Most teams know they should handle scanned PDFs: they handle them by bolting an OCR pass onto the front of the pipeline and calling it done. The failure modes that actually matter are downstream of OCR. Tables lose their column structure when flattened into prose. Diagrams have no text representation at all. Multi-modal source material like depositions, walkthroughs, and recorded proceedings needs to be retrievable alongside the document corpus. None of that is solved by an OCR pass, and all of it is the default state of an enterprise document corpus.
We evaluated managed parsing services on the OmniBench benchmark before building anything in-house. The results made the decision for us:
| Provider | OmniBench score |
|---|---|
| LlamaParse Agentic | 84.9% |
| LlamaParse Cost-Efficient | 71.9% |
| Gemini 3 Flash | 71.0% |
| Reducto | 67.8% |
| Qwen 3 VL | 62.0% |
| Azure Doc Intel | 59.6% |
| Dots OCR | 55.8% |
| Extend | 55.8% |
| Docling (OSS) | 50.6% |
| Google DocAI | 50.4% |
| AWS Textract | 47.9% |
| GPT-5 Mini | 46.8% |
| Haiku 4.5 | 45.2% |
| Landing AI | 45.2% |
Thalamus uses LlamaParse Agentic by default; the parsing layer is configurable, and the right answer for some customers will be a different provider. But OmniBench measures parsing quality in isolation. Real production retrieval depends on parser, chunker, retrieval architecture, and recursion logic working together. A team running LlamaParse Agentic in-house won't get the same end-to-end accuracy as Thalamus running LlamaParse Agentic underneath structure-preserving chunking and recursive retrieval, because the parser score is a precondition for accuracy, not the determinant of it. Building OCR and document parsing in-house when state-of-the-art managed services are this far ahead of in-house alternatives is exactly the kind of "rebuild what's already solved" trap that drains in-house RAG teams. But picking the right parser is the easy part. The architecture around it is the harder problem.
LlamaParse and Cohere are best-in-class for what they do as of writing. They will not be the best forever. The frontier moves every few months, and the configuration that's optimal today will be wrong within a year. The cognitive strain and engineering work to keep up with the changes can be a significant burden on engineering teams focused on shipping features into their products, as the timescales are often much shorter than months and years in today's ML environment.
When buying a Thalamus license, customers aren't simply buying a stack of tools. They're buying the commitment that the research, iteration, and upgrade burden lives on us.
We will swap a parser, a reranker, an embedding model, or an orchestration pattern when something measurably better emerges, and the customer's deployment inherits the upgrade. That's the difference between RAG-as-a-managed-service and a stack you assembled yourself. When you build in-house, that ongoing burden lives on your senior engineers in perpetuity.
p50 looks fine, p99 is where the deal dies
The customer's in-house stack would break with as few as ten concurrent requests. The team had no callback and no real-time visibility into which requests had failed. A single 200-page document took two to three hours to ingest. None of this surfaced during development, because development load is a small number of serial requests issued by the engineering team.
Then onboarding happened. The customer's project managers, contract administrators, and field coordinators started using the system in parallel. The cold vector index, the unbuilt queue, and the opaque ingest pipeline they'd inherited from a managed provider started producing failures the customer experienced and the engineering team didn't see.
In our internal load tests, we measured ingestion against the same document types and volumes the customer was previously running. Standard documents ingest in seconds. Complex documents requiring multiple parsing passes finish in a few minutes. We've ingested 300 multi-format documents in a single batch. The queue adds ingestion latency, but the system holds. Chat and retrieval functionality holds under concurrent load.
The number that matters isn't a benchmark figure on a slide. It's whether the system stays up on the Monday morning of a procurement-driven pilot, when fifty users hit it at once with a cold-start handicap your development environment never imposed. Most in-house RAG pipelines are optimized for the load the developing team generates. That's not the load the customer brings.
The retrieval failure you can't see
Return for a moment to the AIA subcontract incident. The retriever returned a chunk that looked relevant. The chunk supported a plausible-sounding wrong answer. The model synthesized confidently. The output was fluent, cited a source, and was wrong on a question that mattered. The only reason anyone caught it was that the general contractor ran the same query against a second system and noticed they disagreed.
In retrieval-grounded systems, retrieval failures are invisible at the output layer. The output looks correct, sounds correct, and cites a source. The only way to detect a wrong-evidence retrieval is for someone with domain expertise to check the answer against the source. That's exactly what regulated workflows demand. It's exactly what most in-house RAG pipelines aren't architected to support.
The reflexive engineering response is to add a reranker. A cross-encoder reranker reorders retrieval candidates by query-document relevance before the top-k goes to the LLM. It's an easy fix and a real improvement. Thalamus uses a Cohere managed cross-encoder by default, paying a fifty-to-sixty millisecond latency cost for a ten to fifteen percent accuracy lift. The reranker is swappable; what's not swappable is the upstream architecture. In a regulated workflow that tradeoff is obvious. But a reranker reorders what was retrieved. It can't recover what was never retrieved in the first place. The deeper problem is upstream, in how documents become chunks.
The platform's in-house chunker split text on paragraph and stylistic boundaries. The team built bespoke boundary rules that, in their words, took a ridiculous amount of effort to maintain. The output was chunks that didn't align with how contract clauses actually behave. Force majeure provisions, late fee structures, and subcontractor obligations span paragraphs and pages. When a clause spans paragraphs, paragraph-based chunking either splits the clause across chunks or merges it with unrelated content. Either way, the retriever's index doesn't represent the unit of meaning the user is asking about. Confident wrong answers are the predictable consequence.
Thalamus replaces that with structure-preserving semantic chunking in two stages. Stage one is parsing, delegated to LlamaParse, which converts PDFs into structured markdown that preserves headers, tables in markdown and CSV form, and the spatial relationship between images and surrounding text. Stage two is a semantic chunker that splits text into sentences, embeds each sentence with the project's configured embedding model, detects topic shifts by computing cosine similarity between adjacent sentences, and cuts at a configurable percentile threshold of largest semantic distance.
The mechanic that matters is the post-merge pass. After the semantic chunker proposes boundaries, chunks merge within page boundaries until they cross a configurable minimum-character floor. The system never produces stranded one-sentence chunks, and never silently bridges across page breaks. A table on page 12 isn't joined to prose on page 13 just because the embedder thought they were on-topic. Naive chunking treats document structure as noise. Structure-preserving chunking treats it as signal.
Want a teardown of your retrieval architecture?
We'll walk through your ingestion, chunking, retrieval, reranking, and citation flow to identify where enterprise reliability breaks down - and what it would take to close the demo-to-production gap.
Request a DemoSingle-pass retrieval is the wrong shape for the question
Even with structured chunks and a competent reranker, single-pass RAG breaks on a category of question that's common in regulated workflows. The standard pipeline embeds the query, fetches nearest neighbors in the vector index, hands the top-k to the LLM, and generates. That works until the question doesn't decompose into a single semantic neighborhood, and in our customers' verticals, it usually doesn't.
Three failure patterns recur. Dense embeddings underweight exact identifier tokens like a policy number, a statute citation, or a clause label. A query like "what does section 73-A say" can miss the chunk that literally contains "73-A" because the vector representation doesn't preserve the identifier as a high-weight signal. The right answer often lives one page away from the strongest hit, in a table that continues overleaf, a footnote, or a "see prior section" reference that top-k retrieval doesn't follow. And many real questions need staged answering, where the first retrieval reveals what the next query should actually be.
In production with our anchor customers, Thalamus does something different. The agent first decomposes the original query into multiple subqueries.
The question "does this contract require subcontract disclosure?" might decompose into:
- "what does §5.2.1 require regarding subcontractors,"
- "what does §9.6.4 require regarding lender notifications," and
- "what does §5.4 require regarding contract administration."
Each subquery then runs through hybrid retrieval that combines dense vector lookup with exact-match keyword search. Keyword search handles the identifiers and citations that dense embeddings miss; dense vector handles the semantic neighborhood. Each subquery's retrieved chunks then go through adjacent-page expansion, which walks neighboring pages using page-number metadata stored at ingest time, so the retrieval sees the table that continues overleaf. The agent assembles the context across all subqueries and decides whether it's sufficient to answer. If not, it reformulates the decomposition based on what was retrieved and runs the loop again.
This pattern — query decomposition, hybrid retrieval per subquery, sufficiency validation, and recursion — is sometimes called recursive retrieval. It's one component of what we mean by agentic retrieval, not the whole of it.
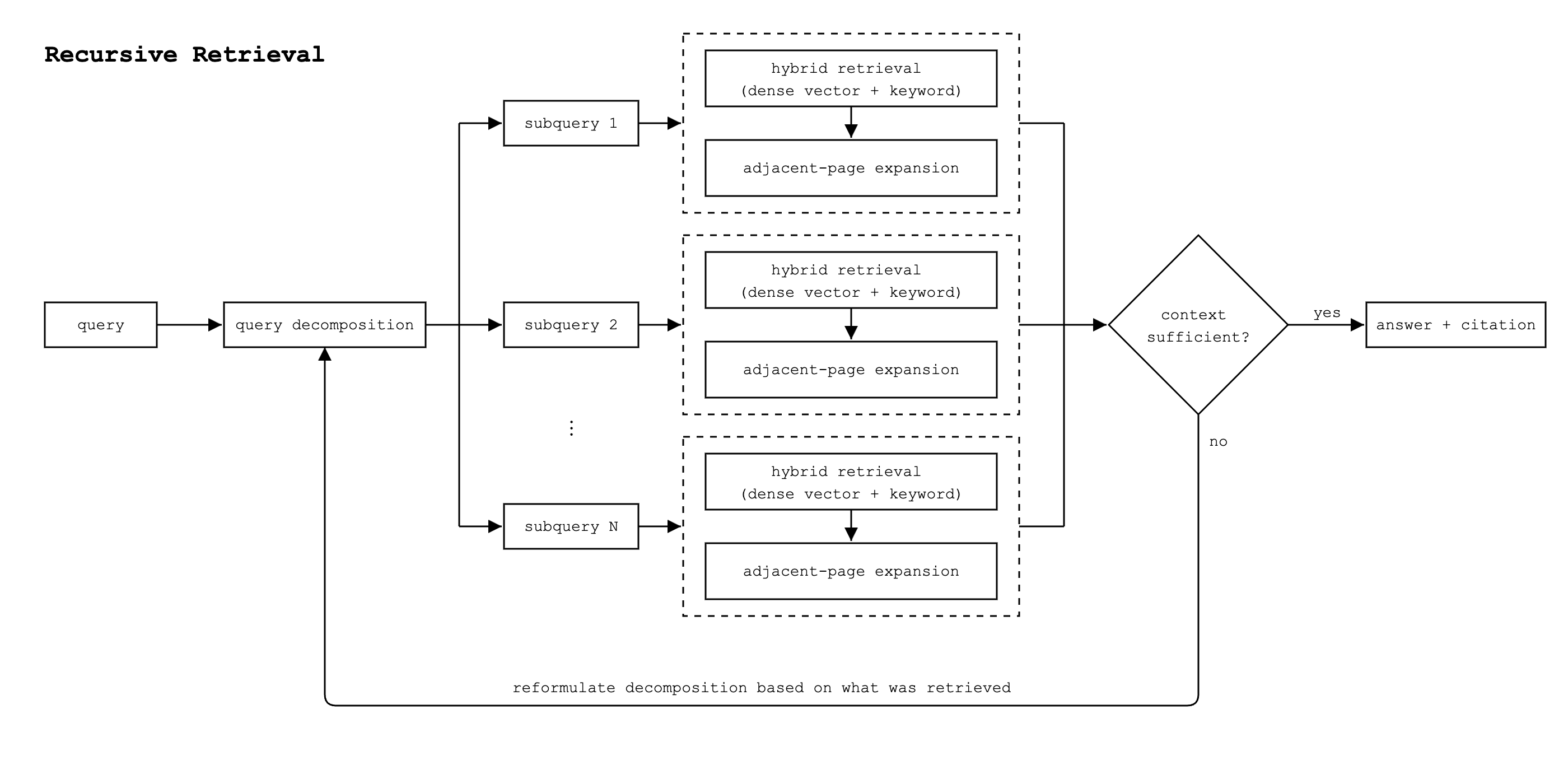
End-to-end retrieval latency on Thalamus runs around three seconds. Single-pass RAG is faster, sometimes sub-second, but it skips the steps that make the result auditable. In a regulated workflow, you don't trade three seconds for a wrong answer. Three seconds buys you context that's been validated, expanded, and cross-checked across retrieval modes. The recursion depth is configurable: workflows that need exhaustive search can run deeper at the cost of more latency, and workflows where speed matters more than thoroughness can cap the loop earlier.
Citation is an architectural commitment, not a feature
By the time a regulated buyer is in late-stage diligence, they are not asking whether your system can show citations in the UI. They are asking whether every retrieved chunk maps back to its source document, whether ingestion controls who can submit what, whether retrieval logs are queryable, and whether a third-party reviewer can reconstruct the evidence chain for a single answer six months after the fact.
The customer had citation tooling in their V1 system. It wasn't used correctly. Citations either weren't generated, weren't traceable back to source documents, or weren't reliable enough for legal review. The AIA subcontract incident is the canonical example. Even when citations were present, the underlying retrieval had pulled the wrong evidence, so the citation pointed at content that didn't actually support the answer. A citation that points at wrong evidence is worse than no citation at all, because it manufactures false confidence.
Citation has to be designed into the ingestion pipeline, the retrieval layer, and the response generation, with controls over who submits documents, who searches, and how every retrieved chunk maps back to its source. In regulated verticals, "the answer is grounded" isn't a UI claim. It's an architectural one.
Stop owning the part of the stack that's quietly burning your senior headcount
The customer built RAG in-house first. Performance was poor. Resource consumption was unsustainable. The architecture couldn't be incrementally fixed. They had to rebuild the underlying architecture first, then migrate, then build new tooling along the way to understand what was breaking, because the original system was a black box. Bad architecture cannot be fixed easily.
We no longer build our own DBs because that's abstracted away and managed better than we should spend time and resources on; the same concept applies to your RAG layer.
Parsing, chunking, retrieval, reranking, citation, and agentic orchestration are solved problems that nobody's senior engineers should be spending their quarters on. The part of your stack that's actually differentiated is the one your customers pay you for. Decide which one is which and staff accordingly.
If you're hitting one of these failure modes, or one we didn't cover, send it over. Happy to do a teardown. The interesting cases are the ones we haven't seen yet.