One of our lead engineers on Thalamus shared that a few years back, as a graduate student preparing for an exam, he ran a small RAG system over his course's textbook. The book was on the shelf. The answers to every assignment were in the book. He even knew which chapter each question was scoped to, but none of that mattered to the retrieval system.
When you chunk a 600-page textbook, each chunk loses its address. The system sees a corpus of ~3,000 semantically similar passages, all written in the same voice and using overlapping terminology. Ask it a question scoped to chapter six and it pulls chunks from chapter one and chapter twelve, ranked by cosine similarity and served up with confidence. The chunks read right, they sound right, but are wrong. The fix our engineer wanted is the same fix production RAG systems need: a way to attach domain-aware metadata to each chunk at ingest, so retrieval knows what each chunk is about before semantic similarity runs. This architecture is called chunk enrichment.
If retrieval could filter to "chunks tagged chapter six" before it scored similarity, the search space would collapse to the right material before the model even ran. That's the underlying pattern behind a class of retrieval failures many RAG systems hit in production. Chunks know what they contain. They don't know what they're about. Most retrieval systems treat every chunk in the index as equivalent and let the embedding model sort it out at query time. The ones that don't, the ones that attach domain-aware metadata to each chunk at ingest and filter against that metadata before semantic search runs, change what's possible. This post is about how chunk enrichment works in production and why in-house RAG teams almost never get around to building it.
"Control" is the wrong word for what CTOs actually want
Our previous blogpost covered why naive RAG fails on long, structured documents. This one is about what changes when retrieval understands the domain.
In an effort to maintain "control" over their retrieval, a CTO we recently spoke to built a RAG system in a matter of only a few days. When this RAG was implemented under their application layer in a production environment, however, it immediately succumbed to miscontextualizing chunks. It pulled semantically similar results, but missed key contextual elements which completely changed its answers to user queries.
In most of our build-vs-buy conversations with customers, the most common objection is control over the stack, not price, risk, or integration cost. Asked to unpack this response, the answer is usually some combination of four things: the ability to make retrieval understand the customer's specific domain, the ability to tune behavior per corpus or per project, the ability to see and adjust how retrieval is being shaped, and the ability to evolve all of that as the product changes. Each of those is a real engineering concern. None of them are about owning the plumbing.
Owning the plumbing, by which most engineers mean running their own embedding model, hosting their own vector database, and writing their own ingestion pipeline, is the default mental model for control because it's how software engineers have thought about control for thirty years. If you own the code, you control the system. But retrieval doesn't work that way. The behavior of a retrieval system is determined by what each chunk in the index knows about itself at the moment a query runs, not by which database it sits on top of.
A system whose chunks carry rich, domain-aware metadata behaves differently from a system whose chunks are anonymous embeddings, regardless of who hosts the database. The first system can filter, classify, and route at retrieval time. The second can only compare similarity scores. The first system is responsive to domain expertise the customer can encode into the schema. The second is responsive to whatever signal the embedding model happens to have learned during pretraining.
The reframe is: what CTOs are actually asking for is retrieval to understand the domain the way the customer understands it. Chunk enrichment is the architecture that delivers that.
Chunk enrichment, mechanically
The mechanism is straightforward to describe and non-trivial to build.
A customer defines a schema, a set of fields that should be extracted from every chunk at ingest. As of now, each field is an LLM prompt with a configurable output format, either a string or a JSON object. We plan to add an agent enrichment field as well however, which will fire off an agent at ingestion to research and add data to this field. The system currently supports two kinds of fields (with a view to continuously add more): a custom prompt field runs a fixed prompt against the chunk and returns structured output. A custom template prompt field does the same with Jinja2 templating, so runtime variables can be injected into the prompt before it executes. Some fields ship as defaults across all schemas, including a chunk ID and a page-level summary that downstream tasks rely on.
At ingest, every chunk passes through the enrichment pipeline. For each field defined in the schema, the system makes one LLM call per chunk, captures the structured output, and stores it alongside the chunk in the index. The original chunk content stays where it was; the enrichment metadata layers on top. All input modalities (text, audio transcripts, video frames, tables, charts) get represented as text in sequence before enrichment runs, which means a schema that classifies a specific kind of content works on a PDF and on a meeting transcript with the same prompt.
Chunk enrichment affects metadata extraction and agentic retrieval routing. The system can filter, classify, and route based on enrichment fields, and an agent layer can decide which fields to consult for a given query. It does not affect base chunking strategy, embedding model choice, or the parsing layer underneath. Those are configured separately. Enrichment is a metadata layer on top of the retrieval pipeline; it doesn't replace your chunking or your embeddings. It adds a structured, domain-aware layer of information that filters what those mechanisms see at query time. Overclaiming the surface area is a credibility risk; this is the honest scoping.
Schemas can be updated mid-project. When a schema is updated, the new version applies to projects created after the update; existing projects keep the version they were ingested under, and historical documents are not reprocessed. Reprocessing every document on every schema change would be prohibitively expensive in compute and would invalidate downstream caches. The cost of that decision is that schema evolution is forward-looking, which is the right tradeoff for most production use cases.
Schema configuration scopes hierarchically. Fields are defined at the group level and used at the project level. A schema defined at the group level applies to all projects in that group. The reason this matters is the question a CTO asks ten minutes into the conversation: if I have ten use cases, do I write ten schemas? No. Per-vertical or per-product-line defaults live at the group level, and multiple groups can be set up. The cascading scope is what makes the architecture tractable at the scale of an actual product portfolio.
What this delivers in practice: a customer in a regulated, document-heavy vertical had previously run an in-house classification pipeline against their core document type. Their own analysis put classification accuracy at around 60%. After moving to chunk enrichment, they defined the relevant categories as enrichment fields, encoded the customer's domain expertise into the prompts, and iterated over two to three days. Accuracy moved to 93-94%, verified against ground truth provided by a domain expert that reviewed the outputs. The lift wasn't about better models. It was about being able to encode what the customer's experts already knew into the structure that retrieval ran against.
Dynamic prompting: one schema, many contexts
The same architecture gets more interesting when enrichment prompts can accept runtime variables.
Consider a customer running tag-and-topic filtering on a large corpus. Their product lets end users define their own approved tag lists, and different users curate different lists for different purposes, and the lists evolve. Without runtime prompting, this is a hard problem. The naive solution is to define a separate schema for every end user, which doesn't scale past a few dozen users and turns schema management into a full-time job. The other naive solution is to hardcode the approved tag set into a single prompt, which collapses the product back to a fixed taxonomy and loses the entire reason the customer offers user-defined tags in the first place.
The mechanism that resolves this is Jinja2 templating in the enrichment prompt itself. A prompt field can include placeholder syntax ({{ approved_tags }}), and at ingest, the system substitutes the runtime-provided value into the prompt before making the LLM call. One schema definition, many runtime configurations. The customer ships a single tag-extraction schema; the per-user tag list gets injected as a variable when that user's documents are processed. The LLM constrains its output to the injected list. Schema management stays bounded; product flexibility doesn't.
The query-time consequence is what makes this concrete. On this customer's corpus, a query without tag filtering would score similarity across roughly 10,000 chunks. With the tag filter applied, it scores across approximately 300, the chunks carrying the tags relevant to the query. The filter runs first; semantic search runs second, against the filtered set. Three things improve simultaneously. Retrieval is faster because the similarity pass runs on a smaller candidate set. It's more accurate because irrelevant chunks are excluded before scoring rather than ranked low after scoring. And it's cheaper because the per-query compute drops with the candidate count. The three usually trade off against each other. Here they don't.
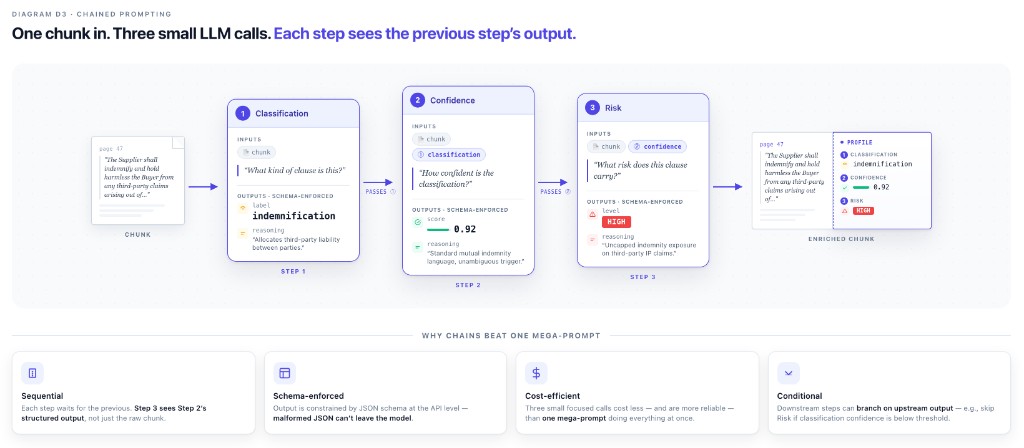
Chained prompting: enrichment that builds on itself
Enrichment fields can be chained. A downstream prompt fires only after an upstream prompt has produced output, and a downstream prompt can be conditional on the upstream output's value. The system currently supports up to three layers of chaining.
The same customer from earlier, the one running classification against domain-expert ground truth, uses a two-layer chain in production. Layer one extracts a relevant passage from the chunk and classifies it against a customer-defined label set, producing a label and the model's reasoning. Layer two evaluates the confidence of that classification, running only after layer one has produced a label, and returns a confidence score (around 90% on representative examples) along with supporting reasoning for the score. The two layers don't run in parallel; the second consumes the output of the first.
The output payload for each chunk after the chain runs looks roughly like this:
{
"page": 47,
"chunk_enrichment": {
"classification": {
"label": "<customer-defined label>",
"reasoning": "<model rationale>"
},
"confidence": {
"score": 0.90,
"reasoning": "<supporting evaluation>"
},
"relevant_text": "<extracted excerpt>",
"summarization": "<chunk-level summary>"
}
}Every field in that payload is queryable downstream. A retrieval query can filter for classifications above a confidence threshold, or surface summaries that contain a specific term, or route only to chunks whose classification falls inside a particular label set. The chain isn't producing metadata for its own sake; it's producing structured affordances that downstream queries can act on.
The three-layer ceiling is deliberate. Each layer adds an LLM call per chunk at ingest, and each layer is a place where the chain can fail, retry, or produce a result the next layer has to handle. Three is the depth where the mechanism stays observable, debuggable, and economically sane. Beyond that, the cost-and-complexity curve bends sharply, and the diagnostic surface area outruns what most teams can maintain in production. The limit is a maturity signal, not a missing feature.
Want to see your corpus enriched?
Send over the schema you'd want to define and the failure modes you're seeing, and we'll show you what the enriched chunk would look like against your actual corpus.
Request a DemoWhere this isn't the right fit
Chunk enrichment is not free, and not every retrieval use case earns the cost.
The first cost is ingest time. Every enrichment field is one LLM call per chunk. A document that ingests in one minute with a default configuration can extend to three to five minutes with three or four enrichment fields. For use cases where the requirement is "ingest tens of thousands of documents today and answer questions tomorrow," that latency budget breaks. Chunk enrichment is the wrong architecture for those workloads. Faster ingestion at lower accuracy is the right tradeoff there, and that's a configuration choice, not a regression.
The second cost is schema quality. The system runs whatever prompt the customer defines. It does not auto-detect a badly constructed schema, doesn't flag prompts that produce inconsistent outputs, doesn't warn when a field is asking the model to do something it can't do reliably. The assumption is that the customer is technical and can write a competent prompt; customers identify problems by observing wrong outputs and iterating. The customer mentioned earlier took two to three days of prompt tuning to reach 93-94% accuracy. That's the work it takes to get a schema to production quality. Customers without that prompt-engineering competence will need services support to get there. We address this issue at Thalamus with an onboarding process with our FDEs that tune this right for our customers’ needs. We are also building the capability to test prompt quality in the tool itself - most likely by ingesting test documents in a sandbox.
The third cost is opportunity. For use cases where retrieval quality isn't the binding constraint, where quick search-and-summarize over a corpus is acceptable with some margin of error, the enrichment overhead isn't justified. Speed and cost win; precision isn't the bottleneck.
Chunk enrichment is the right architecture when retrieval quality is the constraint. When something else is the constraint, the ingest cost and operational complexity buy nothing the workload actually needs.
Why in-house teams predictably don't ship this
Even where chunk enrichment is the right architecture, deciding to build it in-house is a separate question. The economics of that decision are what most build-vs-buy conversations miss.
The enrichment layer itself is roughly two to three months of dedicated MLE work. That estimate assumes production-quality parsing, embedding, retrieval, and telemetry infrastructure is already in place. Most in-house RAG platforms have one or two of those at production quality. The other two are usually "we have something running," which is the version that works for the demo and breaks under real customer corpora. The 2-3 month number is the enrichment layer in isolation; the unstated and bigger investment is everything underneath it.
The telemetry layer is the part most platform teams underestimate. Per-chunk LLM calls at ingest are only economically tractable when the system can track resource consumption at fine granularity (per request, per field, per chunk, per project) and bill against it. Without that telemetry, ingest costs are invisible until the monthly bill arrives and the platform team explains to finance why the AWS spend doubled. Building per-request resource tracking and detailed billing instrumentation isn't on most platform roadmaps until it's an emergency. By the time it's an emergency, the team is six months from having it work properly.
And then there's the roadmap-priority problem. Platform teams operate against a backlog of feature requests from business units. Every quarter, "rebuild chunk handling so retrieval can filter against domain-aware metadata" loses to a specific feature request from a specific product team with a specific revenue case. The platform-side investment is hard to justify in the quarter it would need to happen, because the payoff is downstream and diffuse. If you're hitting the per-corpus tuning wall in month nine of a four-quarter platform roadmap, this is why. It's not that your platform team can't build it. It's that this particular work has lost every prioritization argument it's been in.
The honest version of the build-vs-buy conversation is this. Chunk enrichment is buildable. The mechanism isn't proprietary; the techniques aren't novel. The reason in-house teams predictably don't ship it isn't a competence gap. It's that the work sits at the intersection of "expensive enough to need real engineering investment" and "abstract enough that no product manager will champion it." Those two conditions, together, produce a feature that lives on the roadmap for three years and never gets built.
Retrieval-quality investment lands at ingest
Most retrieval-quality conversations focus on query-time mechanisms: better reranking, smarter query rewriting, agentic decomposition of complex questions. All of those matter. None of them are the leverage point. They're tuning a system that doesn't know what it's looking at.
The leverage point is what each chunk means at the moment it enters the index. A chunk that arrives in the index carrying a classification, a confidence score, a domain-specific tag set, and a structured summary is a different object than a chunk that arrives carrying an embedding. The first object can be filtered, routed, and reasoned about at retrieval time. The second can only be compared. Investing in query-time retrieval quality is investing downstream of the leverage point. Investing in enrichment is changing the search space itself.
Chunk enrichment isn't hard to build. It's hard to prioritize. That's why your platform team didn't ship it.
If you're hitting the per-corpus tuning wall and trying to decide whether to invest another quarter in internal infrastructure, send over the schema you'd want to define and the failure modes you're seeing, and we'll show you what the enriched chunk would look like against your actual corpus.